Replicación en MongoDB
June 18, 2021
Table of contents
Quick Access

En la actualidad existen soluciones que manejan grandes volúmenes de información y usuarios como redes sociales, sistemas bancarios, entre otras, las cuales necesitan permanecer activas durante cualquier eventualidad presentada, digamos, un fallo de luz, red, falla de equipos, lo cual para nosotros como usuarios sería crítico, ¿Te imaginas que se presentara una eventualidad en el banco del cual eres cliente y todo tu dinero simplemente se pierda? o ¿Qué todas las fotos de tu red social favorita de un día para otro no existan?. Si, en un ambiente tan propenso a fallos todas esas situaciones pueden presentarse, de hecho, se presentan, pero es transparente para nosotros ya que los proveedores de servicios como los anteriores implementan soluciones de replicación y alta disponibilidad para prevenir dichas situaciones. La replicación es el proceso de copiar y mantener objetos en múltiples bases de datos para tener un sistema distribuido, permitiendo mejorar el rendimiento y proteger la disponibilidad de las aplicaciones al proporcionar accesos alternativos a los datos.
Todos los gestores de bases de datos modernos ofrecen maneras para poder proporcionar alta disponibilidad y replicación permitiéndoles ser útiles en casos de fallos, pero muchos, si no la mayoría, necesitan de herramientas tercerizadas para poder ofrecer un mecanismo robusto y eficiente, además, a nivel de programación, puede complicarle la existencia a los programadores al ser un poco tediosos al momento de configurar y probar, sin embargo, los creadores y contribuyentes de MongoDB, nos proporcionan una manera bastante sencilla de ofrecer alta disponibilidad y replicación.
En MongoDB la replicación es la forma de proporcionar alta disponibilidad y tolerancia a fallos de forma nativa y transparente a las aplicaciones que lo utilizan como manejador de base de datos, permitiendo a que los programadores no deban ni de entender que sucede detrás del proceso, solo estar seguros de que disponen del mismo y de que es bastante robusto y eficiente. La replicación parte de una colección de instancias o nodos de MongoDB, denominado conjunto de réplicas, en donde siempre debe de existir un nodo primario para poder estar activo.
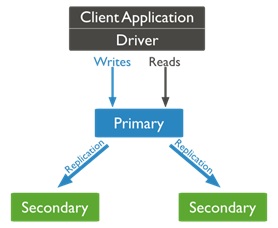
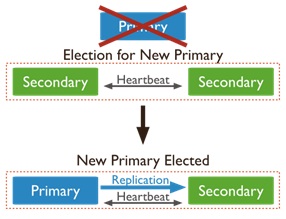
El número mínimo de nodos para conformar un conjunto de réplicas es de tres, ya que en caso de una falla en el primario, un proceso de elección es activado para buscar entre los nodos restantes un único sustituto para seguir proporcionando el servicio. Si solo existen dos nodos, no existiría mayoría en la elección y no se seleccionaría un nuevo nodo primario quedando el conjunto inactivo.
Tipos de nodos
- Regulares: son nodos que tienen los datos y pueden ser tanto primarios como secundarios.
- Árbitro: están ahí solo para enrutamiento y votos; es el que permite que se escoja un nodo como primario en caso de fallo.
- Retrasado: esta un tiempo definido por el usuario por detrás de los demás nodos y se conoce como nodo de desastres.
- Oculto: son nodos mayormente implementados para analíticas.

Proceso de replicación
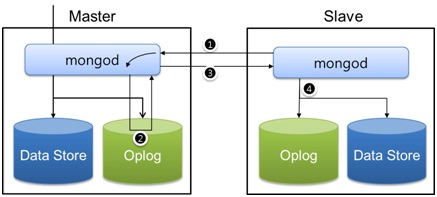
MongoDB implementa una colección especial que guarda registros de recuperación para todas las operaciones que modifican datos, denominada “oplog” o log de operaciones. Las operaciones de modificación se realizan primero en el nodo primario y luego en el oplog del mismo, los secundarios, copian y aplican estas operaciones en procesos ejecutados asíncronamente.
Todos los miembros del conjunto poseen una copia de dicho oplog en la colección: “local.oplog.rs” para poder mantener actualizada su BD. Esto se hace a través de heartbeats o pings a todos los miembros permitiendo importar registros de cualquiera del resto de los nodos en el conjunto. Entonces, en caso de una falla, si un nodo “A” vuelve como secundario después de un periodo bastante largo y el oplog ha iterado en el nuevo primario “B”, se procederá a copiar todos los datos del oplog de “B” en “A”.
Además del oplog, MongoDB implementa dos tipos de sincronización para mantener actualizados todos los nodos de un conjunto de réplicas, el primero es la sincronización inicial para cargar miembros nuevos con todos los datos del conjunto, y el segundo, es la replicación que mantiene los datos actualizados del conjunto luego de la sincronización inicial.
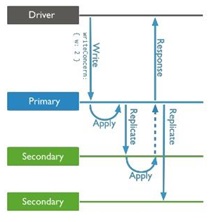
Proceso de escrituras y reconocimiento de escrituras
En la configuración por defecto las escrituras siempre van dirigidas al primario, pero estas pueden configurarse tanto en la conexión con los drivers así como en las llamadas a insert o update según los siguientes parámetros:
- 0: no espera confirmación de que la escritura se realizó con éxito retornando siempre status exitoso.
- 1: es el utilizado por defecto, y retornan status exitoso cuando el nodo primario reconoce los inserts.
- majority: las operaciones de escrituras sólo devolverán status exitoso si la mayoría de los nodos votantes del conjunto reconocen la operación de escritura.
- n: las operaciones de escrituras sólo devolverán status exitoso si la cantidad de nodos votantes especificados según “n” del conjunto reconocen la operación de escritura.
Es importante tener en cuenta que cuando no existe primario no se puede concretar la escritura, pudiéndose presentar casos en los que mongo debe de hacer rollback a los datos en caso que este detecte algún tipo de inconsistencia entre el nodo que solía ser primario y el que pasó a serlo. Otro punto que es necesario conocer, es que si se especifica un número de nodos para el reconocimiento de escrituras mayor al número de nodos existentes, la escritura esperará para siempre.
Lecturas y preferencias de lecturas
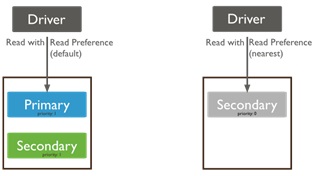
Por defecto, mongo realiza sus lecturas al primario para proporcionar una consistencia fuerte entre los datos escritos con los leídos, sin embargo, permite que este comportamiento sea modificado en su configuración de acuerdo a las necesidades que se tengan:
- primary: modo por defecto; todas las operaciones de lectura van al primario.
- primaryPrefered: permite que las operaciones de lecturas vayan a secundarios en casos que no exista primario disponible para el momento.
- secondary: todas las operaciones de lectura van a los nodos secundarios.
- secondaryPrefered: permite que las operaciones de lecturas vayan a primarios en casos que no existan secundarios disponibles para el momento.
- nearest: las operaciones de lectura van al miembro de conjunto de réplicas que tenga la menor latencia de red, indistintamente de si es primario o secundario.
Aspectos a tener en cuenta al utilizar conjuntos de réplicas de MongoDB en aplicaciones
- Listas de nodos: los drivers necesitan conocer los miembros del conjunto de réplicas (o al menos uno válido) para poder funcionar correctamente. Estos se inicializan al momento de cargar los drivers de mongo del lenguaje con el que se esté trabajando.
- Preferencias de lecturas: la aplicación debe estar preparada para lidiar con datos que en algún momento puedan ser retornados desactualizados al leer de nodos secundarios.
- Reconocimiento de escrituras: si ocurre un error durante una escritura es posible que el driver quede esperando por tiempo indefinido la respuesta de la inserción, lo que es bastante crítico, y nuestra aplicación debe de poder manejar este tipo de situaciones.
- Errores, errores, errores: la aplicación debe de poder manejar excepciones de distintos tipos, ya que no solo se tiene que lidiar con casos como los anteriores, sino también con errores de red, configuraciones del lado de mongo, por nombrar algunas.
Mucha teoría, creemos un conjunto de réplicas desde la consola de mongo
- Identificamos los miembros del conjunto ejecutando desde la consola de cada uno de nuestros nodos: [prism:javascript] mongod --replSet "rs0"; [/prism:javascript]
- Iniciamos el conjunto desde la consola de uno de los miembros: [prism:javascript] rs.initiate(); [/prism:javascript]
- Verificamos el estado de nuestra réplica: [prism:javascript] rs.conf(); [/prism:javascript] Este comando despliega un resultado como el siguiente: [prism:javascript] { "_id" : "rs0", "version" : 1, "members" : [ { "_id" : 1, "host" : " mongodb0.rootstack.com:27017" } ] } [/prism:javascript]
- Añadimos el resto de las instancias de mongo que formarán parte de nuestra réplica: [prism:javascript] rs.add("mongodb1.rootstack.com"); rs.add("mongodb2.rootstack.com"); . . . rs.add("mongodbN.rootstack.com"); [/prism:javascript]
- Listo, tenemos un conjunto replica totalmente funcional. Podemos consultar el estado de nuestra réplica desde uno de los nodos con el comando: [prism:javascript] rs.status(); [/prism:javascript]
En conclusión, el sistema de alta disponibilidad de MongoDB es bastante práctico y sencillo de implementar, robusto y eficiente en su funcionalidad, permite disponer de un ambiente distribuido sin tener que preocuparnos por configuraciones súper extrañas a una serie de componentes que tenemos que enlazar para poder proporcionar un servicio de este tipo, además, el hecho de que como proyecto esté en constante mejoras, actualizado con las necesidades de los programadores, con una comunidad muy grande detrás y cada vez más utilizado por compañías de diferentes rubros, nos permite confiar en que se tomó una buena elección al elegirlo como manejador de base datos.
Espero tengan una mejor comprensión del proceso de replicación en MongoDB, luego estaré posteando sobre el aggregation framework de este, una característica que permite realizar operaciones de consulta como group by (consultas SQL like) a MongoDB, si, a una base de datos NoSQL.
Te recomendamos en video
Related Blogs

Cómo integrar UiPath RPA con una base de datos

Servicios de desarrollo de Magento para la industria de la salud

Las mejores prácticas para contratar a un desarrollador Drupal

5 pasos de la implementación de UiPath RPA

Habilidades que debe tener una empresa de desarrollo de Java para ser un buen socio tecnológico
